
Computer Memory Part 2

Last article we talked about the physical aspects of memory, how it communicates with different components, and how RAM chips work. This time we will combine that with how the memory within the CPU works.
CPU cache
CPU speeds have increased over the years while the speed of RAM chips hasn’t increased in the same pase. As we went over in the last article this is not because there is no faster RAM but because it wouldn’t be economically viable. Therefore it is more common to choose a lot of relatively fast RAM over a small amount of very fast RAM because it is much faster than accessing data on disk so having more space to put stuff in RAM helps us speed up our applications.
This fortunately is not an all-or-nothing deal, we can combine the two and use a bit of both. One way would be to decide on one part of the address space and dedicate it for SRAM and the rest DRAM and rely on the operating system to optimally distribute it. While possible it is not an ideal way of setting it up because mapping physical resources of SRAM to the virtual memory space of the individual processes is hard and also would require every process to administer the allocations of this memory location which would cause a lot of overhead. Every process would want access to this fast memory which would require us to deal with heavy synchronization.
So instead of this approach, it is under the control of the CPU. In this implementation, the SRAM is used to make temporary copies (cache) of data within the main memory which is likely to soon be used. The way this is possible is due to both program code and data having temporal and spatial locality.
Temporal locality refers to data being reused within a relatively small time duration, for example, a call to a function whose address is far away in memory space but a call to this function is made often.
Spatial locality refers to the use of data elements within relatively close storage locations, for example looping over an array in a for a loop.
The CPU caches are not that big on most machines. For example, my machine has 16GB of ram but only 4MB of cache. This is not a problem if the data being worked on is smaller than the cache size but we often want to work on data sets as well as run several processes using memory differently from each other. Because of this, the CPU needs an efficient and well-defined strategy to decide when to cache what.
Cache levels
The CPU cores themselves are not directly connected to the main memory instead they are connected to the cache which acts like a middleman where all the load and store operations first have to go through the cache before it reaches the CPU.
The connection between the cache and CPU is a special fast connection and the connection between cache and main memory is connected via the Front-side bus briefly mentioned in the previous article.
With time when the speed difference between main memory and cache increased, instead of increasing the size of the cache, new caches were added that are bigger and slower. This is to save cost.
That is why we today talk about multiple cache levels where the CPU cache is divided into multiple levels all increasing in size and decreasing in speed. Most common are CPUs with three levels of cache known as the L1, L2, and L3 caches where L1 is the smallest but also the fastest to access while L3 is the slowest but largest.

The L1 and L2 cache are a part of the individual CPU cores while the L3 cache is shared between all cores. Let us talk about how this makes sense. Remember when we briefly mentioned that every load and store operation has to go through the cache first?
Because of this fact, every time memory is needed by the processor the memory is first looked for within the cache. First, the L1 cache is searched then the L2, then L3, and only then the memory is fetched from the main memory. Every time memory is loaded it is also loaded into the cache and once new memory is loaded the old memory is not thrown away but instead pushed into the bigger caches so first it is pushed out of the L1 cache into the L2 cache and then it is pushed into L3 and then in finally to main memory.
This may seem very inefficient but if you compare the speeds of access for different parts of memory you will notice that it’s still more efficient to go through this process than always loading directly from the main memory.
| Destination | Cycles | Size |
| ----------- | ------ | ----------------- |
| Register | ≤ 1 | 8B |
| L1 | ~4 | 32KB |
| L2 | ~12 | 256KB |
| L3 | ~36 | 2 - 45MB (Shared) |
| Main memory | ~230 | - |The above numbers are from my old machine running an intel Haswell chip 3.4 GHz i7-4770.
Cache lines
First of all the processor break the memory up into parts it can reason about and this is known as “cache lines”. The reason for this is if you remember from the previous article that RAM tries to be as efficient as possible by transporting as many words in a row as possible without the need for a new CAS or RAS signal.
A cache line is not a word but instead a line of several words, a cache line is normally 64 bytes of memory and if the memory bus is 64-bit wide this means 8 transfers per cache line.
The memory address for each cache line is computed by masking the value according to the cache line size. For a 64-byte cache line, this means that the low 6 bytes are zeroed and used for the offset into the cache line.
Some number of bits is then taken from the address to choose a set and we are left with 64 - S - 6 bits to form a tag. The chosen set maps the cache line into its own “section” of the cache.

Within the same set, there are several paths and the number of paths corresponds to the number of cache entries of the same set that can occupy that part of the cache. These are different depending on which level of the cache we are in.
So once again the bottom 6 bits tell us where we are within a cache line, the next S bits will tell us which path within the cache we will be looking at. Lastly, there is the Tag which allows us to identify the data that we’re interested in.

Taken from Drepper, Ulrich. “What Every Programmer Should Know About Memory.” (2007).
Why it works this way can be described using this simplified block diagram of a 4-way cache.
At the top, we have an address that is split into a tag, set, and offset. First of all the set is going to be fed into the multiplexers where each of the columns below represents one set. From each row of sets, there is a line which is the path we previously mentioned.
Once a column is selected the data and their tags are fed into a bunch of comparators where the tag from the cache and then the top bits of the address itself are compared where the comparator will compare them and output a one bit if they match and zero if they don’t. If a one bit is emitted it will open up the path for the data which has then been selected.
Multiprocessing
You may have asked yourself how this all works when our machines perform an insane amount of different things at the same time. As we went over before the L1 and L2 caches are unique per core which means that they are shared by hyperthreading but how is it possible for two CPUs to read and write to the same memory if each core has its own set of L1 and L2 caches while keeping a coherent view of the memory?
For this, there is a protocol developed to solve this problem called MESI whose name consists of the four states each cache line can have (Modified, Exclusive, Shared, and Invalid).
Modified: The cache line has been modified locally, this means it’s the only copy within any cache.
Exclusive: The cache line is not modified and known to not be loaded in any other cache.
Shared: the cache line is not modified and might exist in another cache.
Invalid: The cache line is invalid or not used.
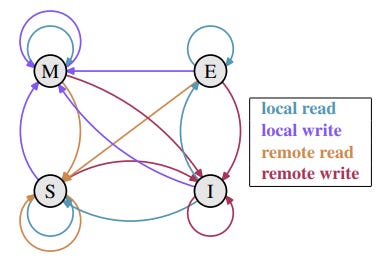
Taken from Drepper, Ulrich. “What Every Programmer Should Know About Memory.” (2007).
Above is a diagram of all the possible state transitions within this protocol. We will go over the most important parts.
Initially, all the cache lines are empty therefore their state is Invalid. If data is loaded into the cache for writing the state will be changed to Modified. If data is loaded for reading the state will depend on whether another processor has the cache line loaded as well, if that is the case the state will be Shared otherwise it will be set to Exclusive.
If a cache line is marked as modified and later read or written to on the same processor the state does not have to change however if a second processor wants to read from the same cache line the first processor has to send the content of its cache to the second processor followed by changing its state to Shared.
When sending the data it is also processed by the memory controller which stores the memory.
If the second processor instead wants to write to the cache line the first processor sends the content over and then marks its cache line locally as Invalid. This is also known as RFO (Request for ownership).
If a cache line is marked as Shared and the local processor wants to read from it no state change is required but if a write operation from another processor is requested then the same type of RFO message is announced and the first processor marks the cache line as invalid.
The Exclusive state is very similar to the Shared state except that a local write operation does not have to be announced on the bus. In this case, the local cache is the only one holding this specific cache line which can be a huge performance advantage.
Thoughts
While this article didn’t go into the more specific parts of the performance benefits of the CPU cache I still found it very informative and useful to understand how to think about the memory within the cache. Combining what we learned here together with what we talked about in the previous article it does make sense to me why we talk about cache lines instead of just cached memory as well as understanding the hierarchical structure of the different cache levels and how they relate.